How to Prepare a Perfect Dataset for AI/ML Scoring Model of GiniMachine
How to Prepare The Ideal Dataset for GiniMachine: A 9-Step Guide
To properly prepare a dataset for GiniMachine, follow these guidelines:
- The dataset should include a target column labeled “ok.” This column represents the historical outcome for each record in the dataset and indicates the status of the loan—whether it has been repaid or is overdue.
- For binary labeling, assign a value of 1 to indicate a repaid loan and a value of 0 to represent an overdue loan.
- Alternatively, other labeling values such as good/bad, repaid/overdue, or stayed/churned can also be used for various decision-making scenarios.
Step #1 Meet The Minimum Requirements
To ensure a quality model, it is recommended to have a minimum of 1000 records in your dataset. These records should include a diverse range of data, such as 870 good loans and 130 bad loans, for example.
GiniMachine supports file formats such as xlsx, csv, and xls. The cells within the files can contain text, numbers, or dates.
Step #2 Include Recommended Attributes
The list of recommended attributes includes but it not limited to:
- Social and demographic data about applicants (gender, age, education, marital status, number of children)
- Geographical data (residence, country, city)
- Employment data (profession, present employment duration, total work experience)
- Data about employers (industry, company size, location: city, region)
- Credit history data (total amount of debt, number of open contracts, total number of delinquencies)
- Parameters calculated by the lender (debt-to-income ratio, payment-to-income ratio , total loan debt)
- Alternative data (behavioral data, payment data from telecom and utility service providers)
Note: it’s recommended to include a maximum of 50 values.
Step #3 Clear Formatting
This step is straightforward. Just ensure that your dataset is free from hidden symbols and unnecessary spaces, as they can cause confusion and lead to inaccurate results.
Step #4 Remove Duplicates
It’s as simple as that. Ensure that there are no duplicate entries in your dataset. If duplicates exist, they can compromise the quality of visual representation and analysis.
Step #5 Remove Irrelevant Data
Consider removing URLs, HTML tags, tracking codes, and unnecessary blank spaces in the text. Also, when analyzing creditworthiness, it’s reasonable to remove personal data like names and email addresses.
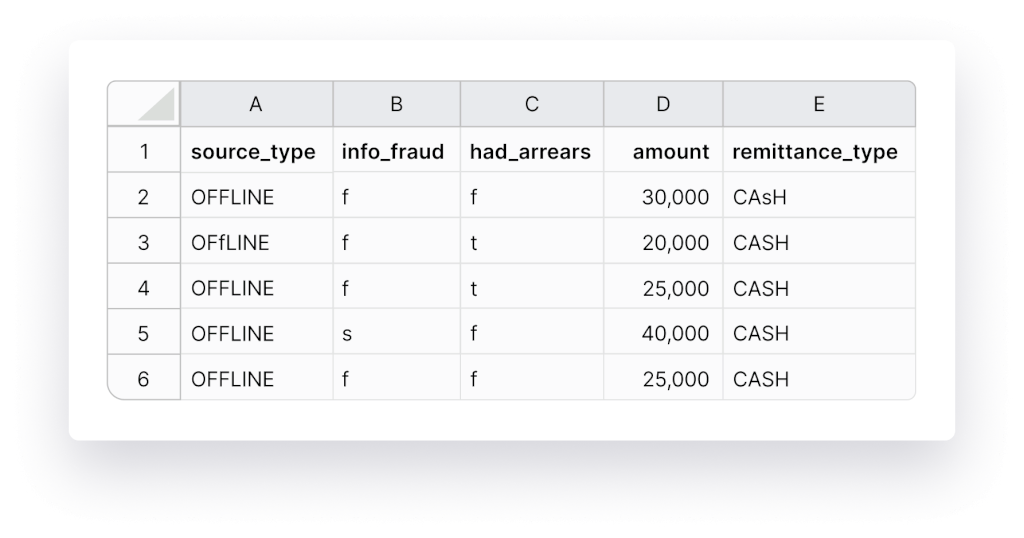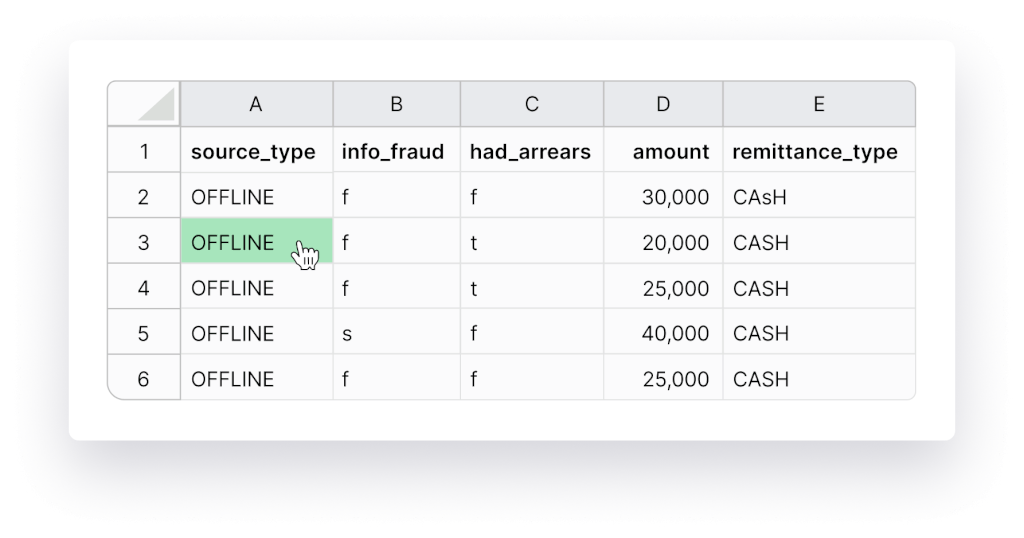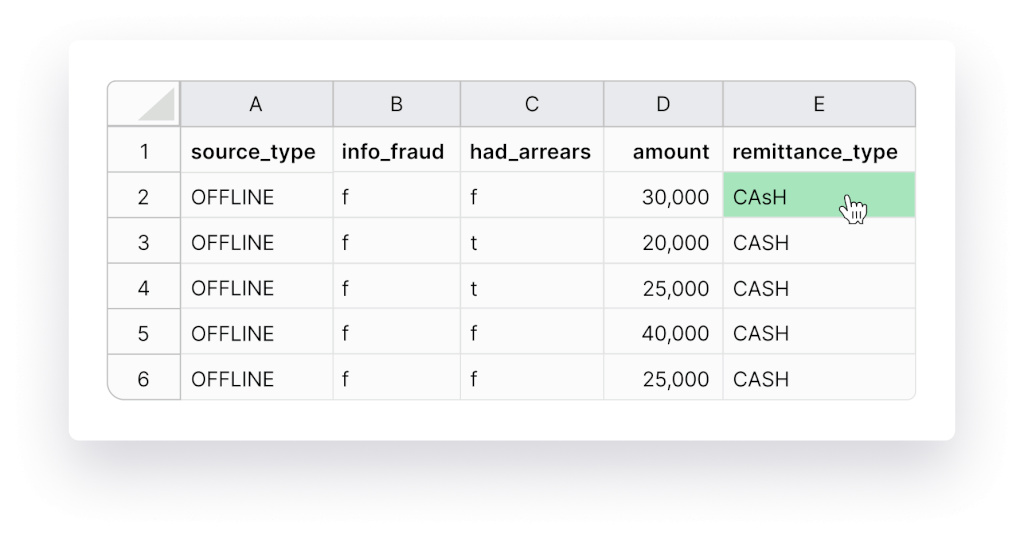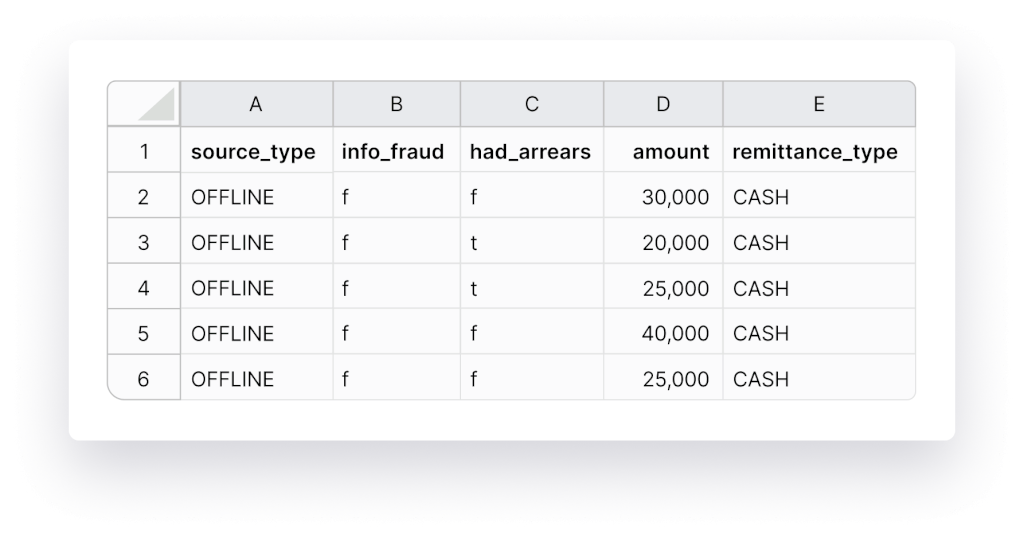
Step #6 Use Numbers For Dates
AI and machine learning thrive on numbers, so let’s simplify their task. Ensure consistency by replacing “June 29th, 1990” with “06/29/1990”. Also, maintain uniformity in currencies and measurements. Convert fields with amounts in US dollars and Euros to the same currency. Similarly, standardize country names, such as consistently using “US” or “United States of America”.
Step #7 Standardize Capitalization
Consistency matters not just for AI but also for us humans. “Bill” and “bill” have different meanings, so ensure your data follows a single capitalization standard throughout.
Step #8 Eliminate Errors
The dataset is not the place for typos, misspelled words, or punctuation errors. Accuracy is essential.
Step #9 One Language At a Time
Most NLP models are designed to handle one language at a time, that’s why it’s essential to stick to one language in a particular dataset.

No Time for Data Cleaning? Here’s The List of Tools to Help You Out!
A lack of time is totally understandable but it doesn’t make data cleaning unnecessary. At GiniMachine, we’re constantly using various tools to speed up the process, and these four are our favorites:
- Tableau Prep is best suited for companies that prioritize data visualization and analysis.
- Tibco Clarity is ideal for organizations that require robust data integration and governance solutions. It helps streamline data processes, ensuring data accuracy, consistency, and compliance with data governance policies.
- Informatica Cloud Data Quality is a cloud-based data quality tool that focuses on improving data accuracy, completeness, and consistency.
- Oracle Enterprise Data Quality caters to organizations using Oracle’s ecosystem and offers data profiling, cleansing, and matching capabilities. Oracle Enterprise Data Quality ensures high-quality data for reliable business insights and efficient operations within Oracle environments.
To Sum Up
Data cleaning and the prep work may appear daunting, but it serves as the essential groundwork for making informed and unbiased decisions. In this article, we have outlined 9 fundamental steps of this critical process. While there may be additional steps, GiniMachine is an advanced tool that can handle much of the work for you. Powered by robust AI/ML algorithms, GiniMachine simplifies and automates the data cleaning process, using the cleaned dataset for informed decision-making.
